



بشكل عام ، يشمل تحليل البيانات تحليل البيانات المنظمة وغير المنظمة. الأول هو على سبيل المثال تحليل البيانات المهيكلة في تنسيق قائمة مشتركة ، بينما الأخير هو لتحليل البيانات في تنسيقات غير منظمة مثل النص والصور ومقاطع الفيديو. في الواقع ، على غرار البيانات المهيكلة ، يعد النص العادي أيضًا تنسيقًا شائعًا للبيانات.
تستخرج تحليلات النص الأنماط والرؤى المفيدة للمستخدمين النهائيين عن طريق تحليل البيانات النصية غير المهيكلة إلى نموذج أكثر تنظيماً باستخدام تقنيات مثل معالجة اللغة الطبيعية (NLP) واسترجاع المعلومات والتعلم الآلي (ML).
تقنيات مثل تصنيف النص وتجميع النص وتحليل المشاعر وتحليل التشابه ونمذجة العلاقة هي تقنيات تحليل النص الشائعة.
بالنسبة لبيانات النص غير المهيكلة ، نحتاج إلى استخدام مجموعة أدوات لغة Python الطبيعية NLTK (مجموعة أدوات لغة Python الطبيعية) للتحليل. يتضمن NLTK ، الذي نشأ في عام 2001 وصمم في الأصل للتدريس ، مجموعة عينة نصية تسمى corpora. من الواضح أن تحليل النص غير المنتظم يتطلب منا الحصول على NLTK أولاً.


01

انقر فوق الزر تحديث في الزاوية اليمنى السفلية من NLTK Downloader ، وقم أولاً بتعديل عنوان URL الموجود على الجانب الأيمن من فهرس الخادم إلى "https://www.nltk.org/nltk_data" على موقع NLTK الرسمي ؛
بعد تحديد حزمة التثبيت المراد تنزيلها ، انقر فوق "تنزيل" لتنزيل مجموعة nltk_data إلى المجلد "C: \ Users \ Administrator \ AppData \ Roaming \ nltk_data" ، انظر الشكل 1.
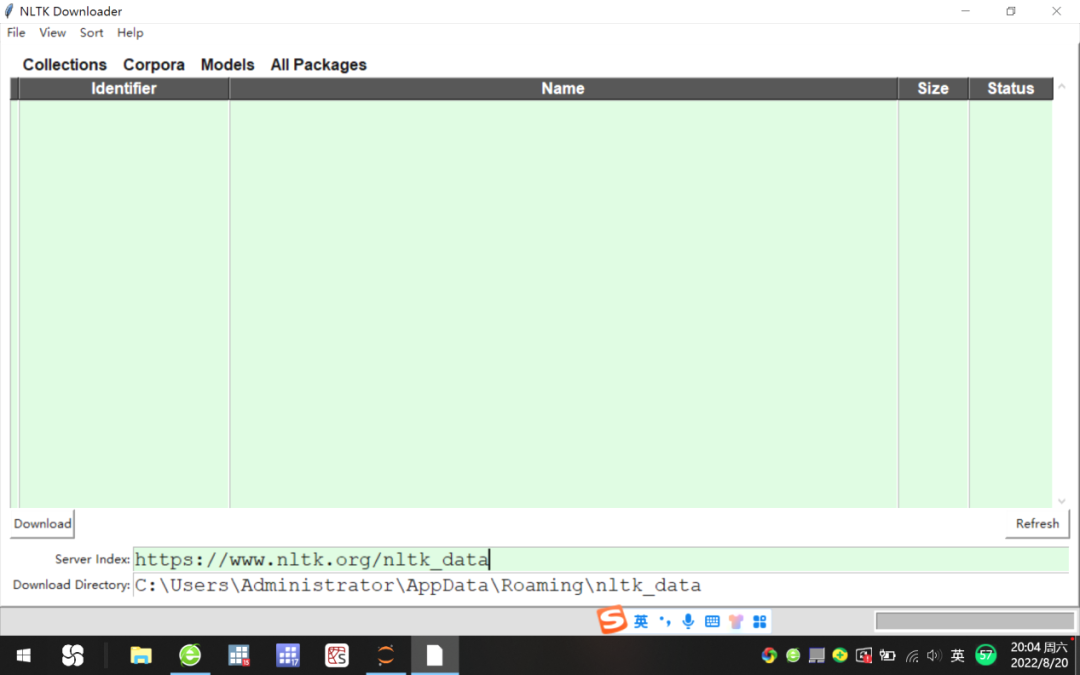
الشكل 1 قم بتنزيل ملف nltk corpus من الموقع الرسمي
تصل سعة مجموعة nltk التي يتم تنزيلها من الموقع الرسمي إلى 1.8 جيجابايت ، وسرعة التنزيل بطيئة. بديل عملي هو استخدام Baidu Cloud لتنزيل الحزمة المضغوطة ، على حساب فك ضغط كل ملف مضغوط يدويًا في nltk_data.zip.

02
أدخل رابط الملف التالي في شريط البحث لمتصفح 360: "https://pan.baidu.com/s/1LWM3o7iRZMF8XaD91vx9Dw" ، أدخل رمز التحقق الديناميكي الذي أرسله الهاتف المحمول لفتح قرص شبكة Baidu ، و ثم أدخل كود الاستخراج "cnpf" لتنزيل الحزمة المضغوطة nltk_data.zip ، انظر الشكل 2.
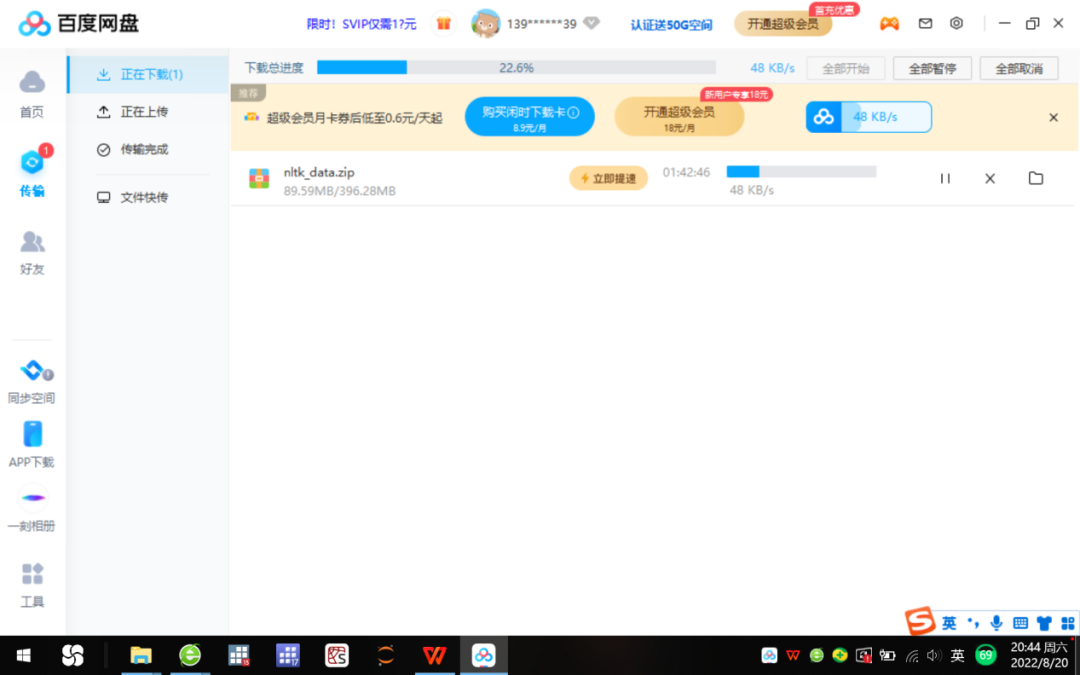
الشكل 2 الشكل 2 Baidu cloud download nltk corpus
قم بفك ضغط الحزمة المضغوطة التي تم تنزيلها ، يمكنك الحصول على 9 مجلدات فرعية مثل chunkers ، corpora ، إلخ. وضعناها في مسار دليل التنزيل "C: \ Users \ Administrator \ AppData \ Roaming \ nltk_data" ، انظر الشكل 3.
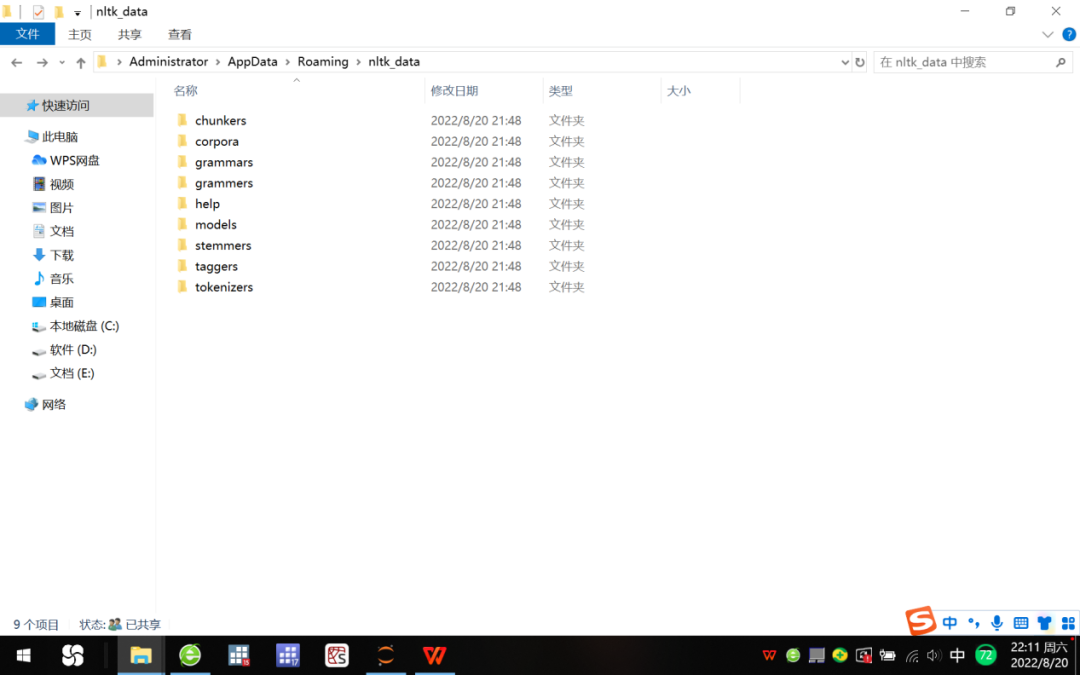
الشكل 3 9 مجلدات فرعية موجودة في مجلد nltk_data
03
افتح Jupyter Notebook ، وانقر فوق الزر New الموجود على اليمين لإنشاء ملف Python جديد ، وأدخل الأوامر التالية بدورها للتحقق مما إذا تم تنزيل مجموعة nltk بنجاح ، انظر الشكل 4.

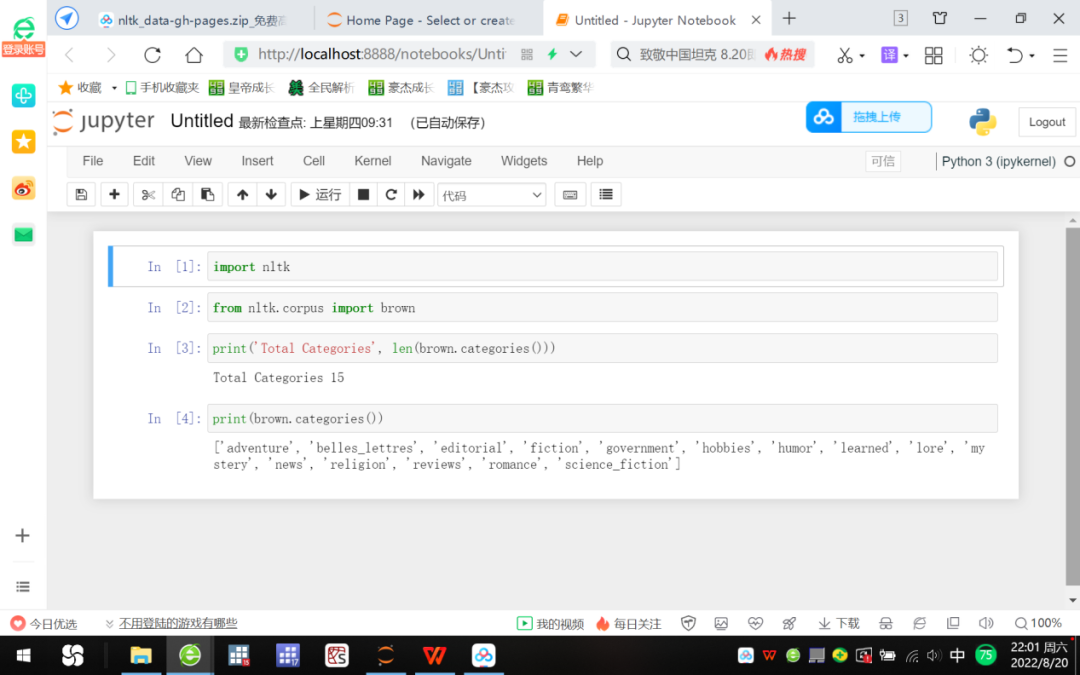
الشكل 4 اختبار تنزيل nltk: الوصول إلى مجموعة براون
براون هي أول مجموعة تعليمية باللغة الإنجليزية في العالم من مستوى المليون ، والمعروفة أيضًا باسم "مجموعة المعايير الأمريكية المعاصرة للغة الإنجليزية" ، والتي طورها كوتشيرا وفرانسيس من جامعة براون في عام 1961. تتكون المجموعة من نصوص من مصادر وتصنيفات مختلفة.
تخبرنا نتيجة تنفيذ الأمر في الشكل 4 أن هناك 15 نوعًا في المجموعة ، مثل الأخبار (الأخبار) ، والغموض (الغموض) ، والأسطورة (الخيال) ، وما إلى ذلك ، مما يشير إلى أنه تم تثبيت مجموعة nltk الأصلية بنجاح.
04
يحتوي NLTK على Gutenberg Corpus ، وهو مشروع مكتبة رقمية يمكن للأشخاص قراءته على الإنترنت.
1. قم بفك ضغط حزم gutenberg و punkt و stopwords والكلمات المضغوطة في المجلد الفرعي corpora nltk_data ، انظر الشكل 5 .
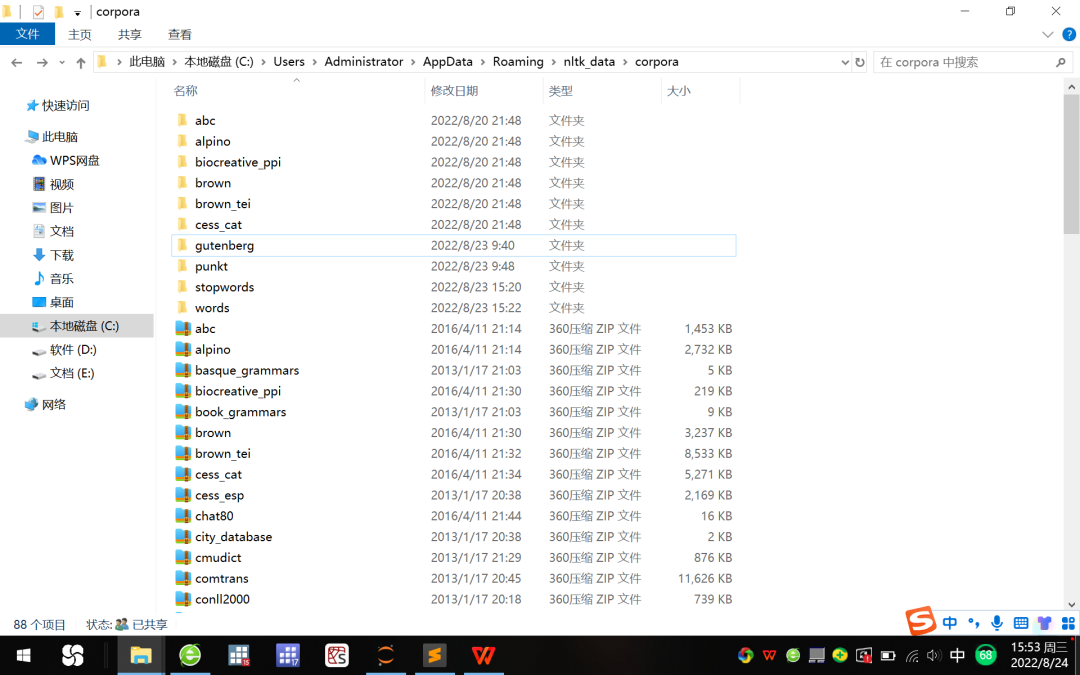
الشكل 5 ضغط المجلد الفرعي nltk_data
2. قم بإنشاء مجلد فرعي PY3 جديد في المسار التالي ، ثم ضع ملف english.pickle في هذا المسار في المجلد الفرعي PY3 المنشأ حديثًا ، انظر الشكل 6.
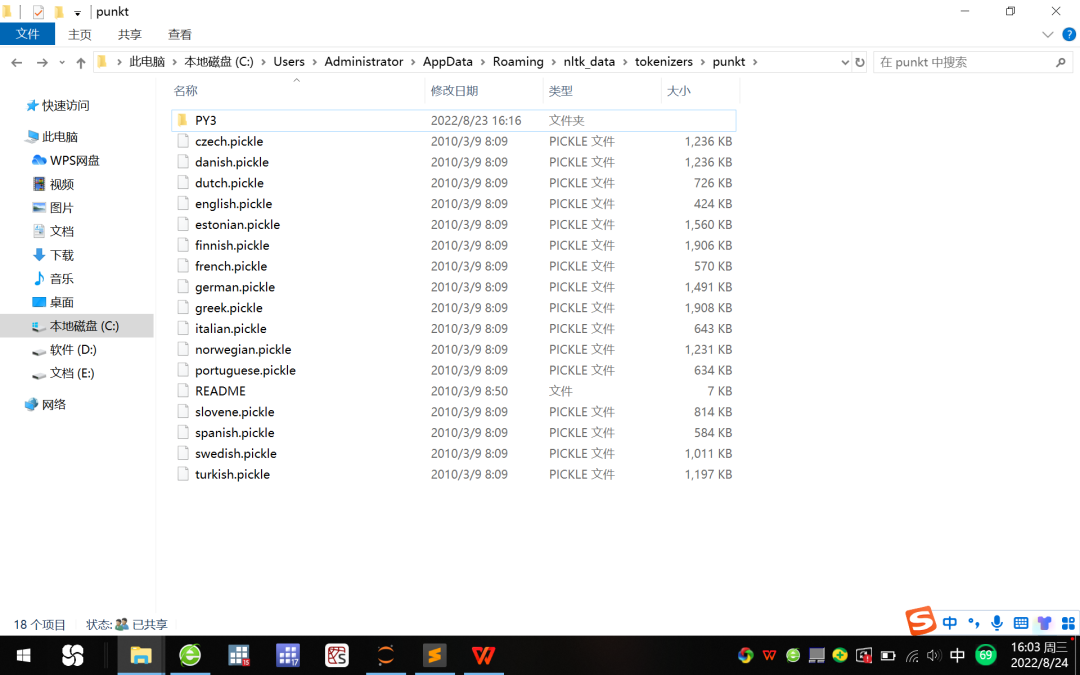
الشكل 6 مجلد فرعي جديد PY3
3. افتح Jupyter Notebook ، وانقر فوق الزر "جديد" على اليمين لإنشاء ملف Python جديد ، وأدخل الأوامر التالية بدورها: انظر الشكل 7 والشكل 8 لمعرفة النتائج الجارية.

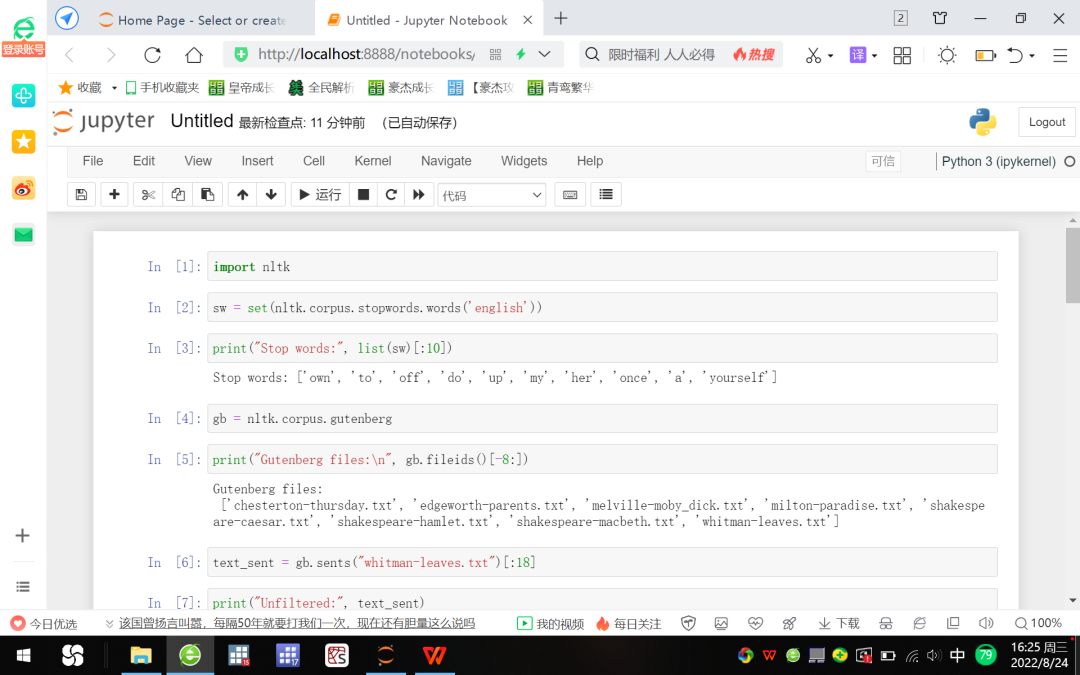
الشكل 7 العرض التوضيحي للغة البرمجة اللغوية العصبية استنادًا إلى Jupyter Notebook
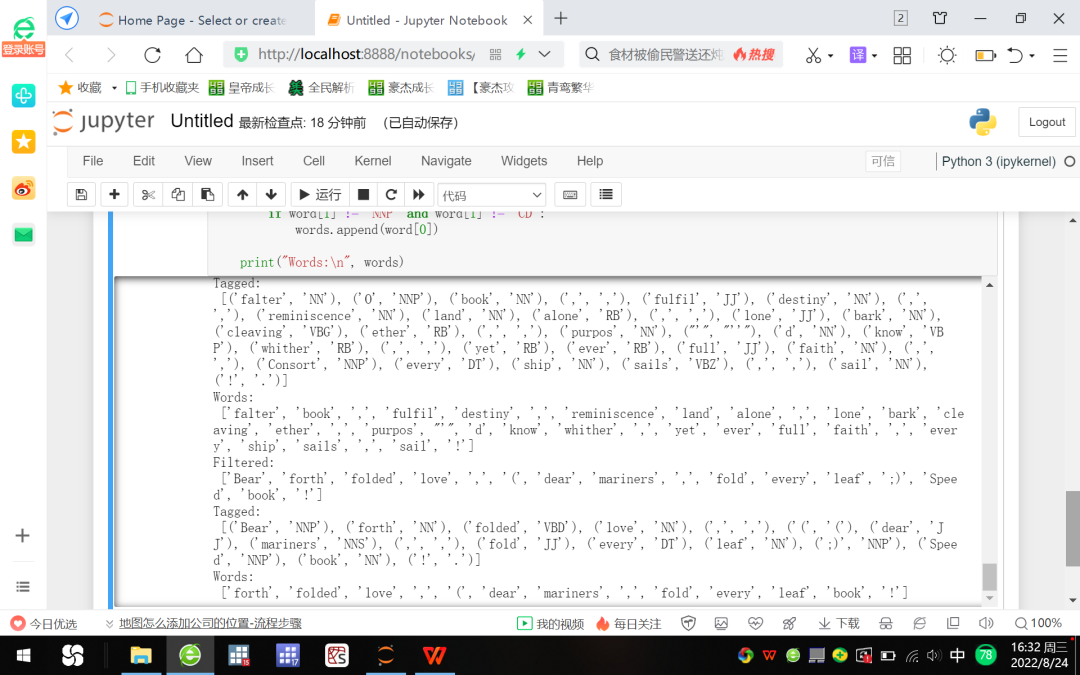
الشكل 8 عرض توضيحي للغة البرمجة اللغوية العصبية لتصفية كلمات التوقف والأسماء والأرقام: استنادًا إلى مشروع جوتنبرج
يوضح الشكل 8 أنه تمت تصفية كلمات الإيقاف والأسماء والأرقام من قائمة الكلمات.

المحرر: Cao Chengzhou
مراجعة: Yang Lu

المراجعات السابقة:
سلسلة تحليل بيانات Python الثامنة: الترابط بين تحليل بيانات Python و Stata
السلسلة السابعة لتحليل بيانات بايثون: تحليل الانحدار المتعدد
سلسلة تحليل بيانات Python الرابعة: المعالجة المسبقة للبيانات
سلسلة تحليل بيانات بايثون الثالثة: الإحصاء الوصفي

مقدمة في المحاسبة التجريبية أصبحت سهلة
امسح رمز الاستجابة السريعة لمتابعتنا
Dingyuan Accounting WeChat Group
موضوع هذه المجموعة:
تبادل Stata مع Python ،
تحليل البيانات المنظمة ،
استكشاف محاسبة النص غير المهيكلة ،
اكتب حياة Dingyuan Accounting معًا .