
[ملاحظة محرر CSDN] يستخدم مؤلف هذا المقال مثالاً لبرنامج لشرح عملية تحسين الأداء لقراءة البيانات وكتابتها عبر أنابيب لينكس ، وزيادة الإنتاجية من 3.5 جيجا بايت / ثانية إلى 65 جيجا بايت / ثانية النهائية. حتى لو كان مجرد مثال صغير ، فإنه يتضمن الكثير من نقاط المعرفة ، بما في ذلك عمليات النسخ الصفري ، والمخازن المؤقتة للحلقة ، والذاكرة الافتراضية والذاكرة الظاهرية ، وأعباء المزامنة ، وما إلى ذلك ، خاصة بالنسبة لمفاهيم مثل الربط ، والترحيل ، وعنوان الذاكرة الظاهرية رسم الخرائط في Linux kernel محلل من مستوى المصدر. من المفهوم إلى الكود ، تتقدم المقالة من السطحية إلى العميقة ، طبقة تلو الأخرى. على الرغم من أنها تركز على تحسين أداء القراءة والكتابة في خط الأنابيب ، أعتقد أن مطوري التطبيقات عالية الأداء أو Linux kernel سيستفيدون كثيرًا منه .
الرابط الأصلي: https://mazzo.li/posts/fast-pipes.html
ملاحظة: تمت ترجمة هذه المقالة بواسطة منظمة CSDN ، ويحظر إعادة الطباعة غير المصرح بها!
تبحث هذه المقالة في كيفية تنفيذ أنابيب Unix في Linux عن طريق التحسين التكراري لبرنامج اختبار يقوم بكتابة البيانات وقراءتها عبر الأنابيب.
لقد بدأنا ببرنامج بسيط بسعة نقل تبلغ حوالي 3.5 جيجا بايت / ثانية وزدنا أداءه تدريجيًا بمقدار 20 ضعفًا. تم تأكيد تحسين الأداء عن طريق استخدام ملف تعريف أدوات الأداء لنظام Linux ، الكود متاح على GitHub (https://github.com/bitonic/pipes-speed-test).
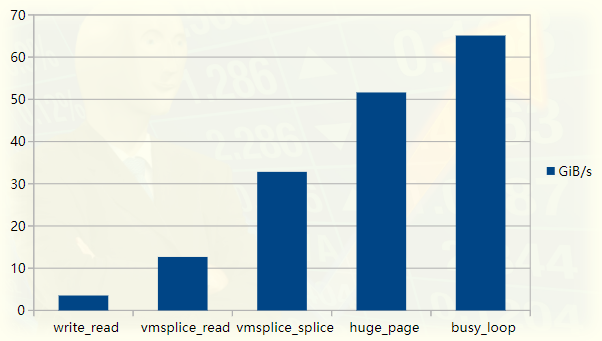
الرسم البياني لأداء اختبار خط الأنابيب
هذه المقالة مستوحاة من قراءة برنامج FizzBuzz المحسن للغاية. على جهاز الكمبيوتر المحمول الخاص بي ، يقوم البرنامج بدفع الإخراج إلى أنبوب بسرعة حوالي 35 جيجا بايت / ثانية. هدفنا الأول هو تحقيق هذه السرعة وسنصف كل خطوة في عملية التحسين. سيتم إضافة تحسين إضافي للأداء غير مطلوب في FizzBuzz لاحقًا ، نظرًا لأن عنق الزجاجة هو في الواقع إخراج الحوسبة ، وليس الإدخال / الإخراج ، على الأقل على جهازي.
سنمضي على النحو التالي:
-
الأول هو نسخة بطيئة من معيار خط الأنابيب ؛
-
اشرح كيف يتم تنفيذ خط الأنابيب داخليًا ، ولماذا تكون القراءة والكتابة منه بطيئة ؛
-
اشرح كيفية استخدام استدعاءات نظام vmsplice و splice لتجاوز بعض حالات البطء (ولكن ليس كلها!) ؛
-
اشرح صفحات Linux ، واستخدم صفحات ضخمة لتنفيذ إصدار سريع ؛
-
استبدال الاستقصاء بحلقة مشغولة للتحسين النهائي ؛
-
لخص
الخطوة 4 هي أهم جزء في Linux kernel ، لذلك قد تكون ذات أهمية حتى إذا كنت على دراية بالموضوعات الأخرى التي تمت مناقشتها في هذه المقالة. للقراء الذين ليسوا على دراية بالموضوع ، نفترض أنك تعرف فقط أساسيات لغة سي.

تحدى النسخة الأولى البطيئة
لنختبر أولاً أداء برنامج FizzBuzz الأسطوري وفقًا لقواعد النشر الخاصة بـ StackOverflow :
% ./fizzbuzz | pv >/dev/null422GiB 0:00:16 [36.2GiB/s]
يرمز pv إلى "عارض الأنبوب" وهو أداة يدوية لقياس سرعة تدفق البيانات عبر الأنبوب . يظهر هو fizzbuzz ينتج الإخراج بسرعة 36 جيجا بايت / ثانية.
يكتب fizzbuzz الإخراج في أجزاء كبيرة مثل ذاكرة التخزين المؤقت L2 لتحقيق توازن جيد بين الوصول الرخيص إلى الذاكرة والحد الأدنى من عمليات الإدخال والإخراج.
على جهازي ، ذاكرة التخزين المؤقت L2 هي 256 كيلوبايت. تنتج هذه المقالة أيضًا كتل 256 كيلو بايت ، ولكنها لا تقوم بأي "عملية حسابية". نريد أساسًا قياس الحد الأعلى على معدل نقل البرنامج الذي يتم كتابته إلى أنبوب بحجم معقول للمخزن المؤقت.
يستخدم fizzbuzz pv لقياس السرعة ، وسيكون إعدادنا مختلفًا قليلاً: سنقوم بتنفيذ البرامج على طرفي الأنبوب ، لذلك لدينا سيطرة كاملة على الكود المتضمن في دفع البيانات وسحبها من الأنبوب.
الكود متاح في مندوب اختبار سرعة الأنابيب الخاص بي . الكتابة.cpp تنفذ الكتابة ، وتنفذ read.cpp القراءة. الكتابة تحتفظ بكتابة نفس 256 كيلوبايت بشكل متكرر ، تنتهي القراءة بعد قراءة 10 جيجا بايت من البيانات ، وتطبع الإنتاجية في جيجابايت / ثانية. يقبل كلا البرنامجين التنفيذيين خيارات سطر الأوامر المتنوعة لتغيير سلوكهم.
سيستخدم الاختبار الأول للقراءة والكتابة من الأنبوب مكالمات نظام الكتابة والقراءة ، باستخدام نفس حجم المخزن المؤقت مثل fizzbuzz. يظهر رمز جانب الكتابة أدناه:
int main() {size_t buf_size = 1 << 18; // 256KiBchar* buf = (char*) malloc(buf_size);memset((void*)buf, 'X', buf_size); // output Xswhile (true) {size_t remaining = buf_size;while (remaining > 0) {// Keep invoking `write` until we've written the entirety// of the buffer. Remember that write returns how much// it could write into the destination -- in this case,// our pipe.ssize_t written = write(STDOUT_FILENO, buf + (buf_size - remaining), remaining);remaining -= written;}}}
من أجل الإيجاز ، تم حذف جميع عمليات التحقق من الأخطاء في مقتطفات التعليمات البرمجية هذه واللاحقة. بالإضافة إلى التأكد من أن المخرجات قابلة للطباعة ، فإن memset تخدم غرضًا آخر ، والذي سنناقشه لاحقًا.
تم الانتهاء من جميع الأعمال باستخدام مكالمة الكتابة ، والباقي هو التأكد من كتابة المخزن المؤقت بالكامل. جانب القراءة مشابه جدًا ، فقط يقرأ البيانات في buf وينتهي عند قراءة بيانات كافية.
بمجرد الإنشاء ، يمكن تشغيل الكود الموجود في المستودع على النحو التالي:
./write | ./read3.7GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
نكتب إلى نفس المخزن المؤقت 256 كيلوبايت المملوء بـ 40960 مرة "X" ونقيس الإنتاجية. بشكل مزعج ، إنه أبطأ 10 مرات من fizzbuzz! نكتب البايت على الأنبوب ولا نفعل شيئًا آخر. اتضح أنه لا يمكننا الحصول على أسرع من ذلك باستخدام الكتابة والقراءة.

مشكلة الكتابة
لمعرفة الوقت المستغرق في تشغيل البرنامج ، يمكننا استخدام perf:
% perf record -g sh -c './write | ./read'3.2GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)[ perf record: Woken up 6 times to write data ][ perf record: Captured and wrote 2.851 MB perf.data (21201 samples) ]
يرشد الخيار -g perf إلى تسجيل الرسم البياني للمكالمات: وهذا يسمح لنا بمعرفة المكان الذي يقضيه الوقت من أعلى إلى أسفل.
يمكننا استخدام تقرير الأداء لمعرفة أين يقضي الوقت. إليك مقتطف تم تعديله قليلاً يوضح بالتفصيل الوقت المستغرق في الكتابة:
% perf report -g --symbol-filter=write- 48.05% 0.05% write libc-2.33.so [.] __GI___libc_write- 48.04% __GI___libc_write- 47.69% entry_SYSCALL_64_after_hwframe- do_syscall_64- 47.54% ksys_write- 47.40% vfs_write- 47.23% new_sync_write- pipe_write+ 24.08% copy_page_from_iter+ 11.76% __alloc_pages+ 4.32% schedule+ 2.98% __wake_up_common_lock0.95% _raw_spin_lock_irq0.74% alloc_pages0.66% prepare_to_wait_event
يتم إنفاق 47٪ من الوقت على pipe_write ، وهو ما تفعله الكتابة عندما نكتب على الأنبوب. هذا ليس مفاجئًا - لقد أمضينا حوالي نصف الوقت في الكتابة والنصف الآخر في القراءة.
في pipe_write ، يتم قضاء 3/4 الوقت في نسخ الصفحات أو تخصيصها (copy_page_from_iter و __alloc_page). هذا منطقي إذا كان لدينا بالفعل فكرة عن كيفية عمل الاتصال بين النواة ومساحة المستخدم. في كلتا الحالتين ، لفهم ما يحدث تمامًا ، يجب أن نفهم أولاً كيفية عمل الأنابيب.

من ماذا تصنع الأنابيب؟
يمكن العثور على هياكل البيانات التي تحدد الأنابيب في include / linux / pipe_fs_i.h ، والعمليات عليها في fs / pipe.c.
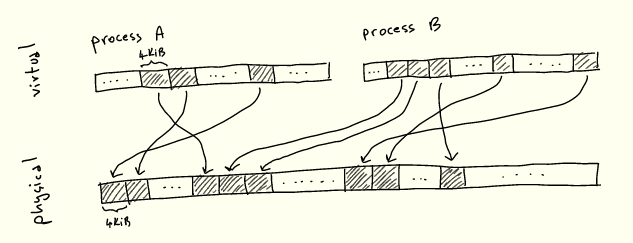
أنبوب Linux عبارة عن مخزن مؤقت يحتوي على مراجع للصفحات حيث تتم كتابة البيانات وقراءتها:
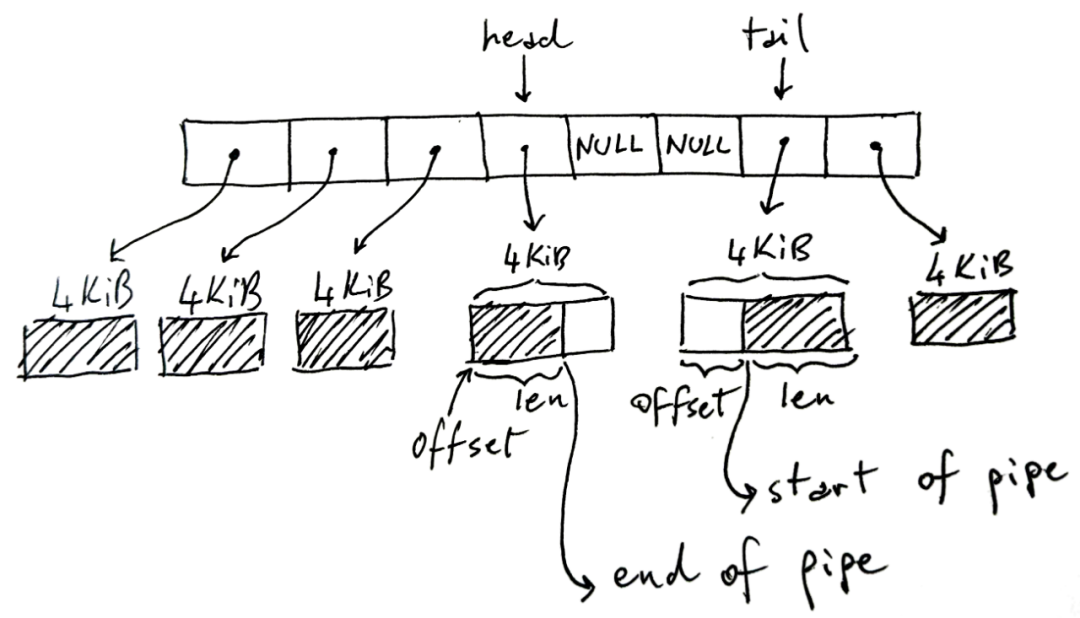
يحتوي المخزن المؤقت للحلقة في الصورة أعلاه على 8 فتحات ، ولكنه قد يكون أكثر أو أقل ، والافتراضي هو 16. يبلغ حجم كل صفحة 4 كيلوبايت في بنية x86-64 ، ولكن قد يختلف في البنى الأخرى. يمكن أن يحتوي الأنبوب على إجمالي 32 كيلوبايت من البيانات. وإليك نقطة أساسية: كل أنبوب له حد أعلى للمقدار الإجمالي للبيانات التي يمكنه الاحتفاظ بها قبل أن تملأ.
يمثل الجزء المظلل في الشكل بيانات خط الأنابيب الحالية ، ويمثل الجزء غير المظلل المساحة الخالية في خط الأنابيب.
بشكل غير متوقع إلى حد ما ، يخزن الرأس نهاية الكتابة لخط الأنابيب. أي أن الكاتب سيكتب إلى المخزن المؤقت المشار إليه برأسه ، ويزيد الرأس وفقًا لذلك إذا احتاج إلى الانتقال إلى المخزن المؤقت التالي. في المخزن المؤقت للكتابة ، يخزن len مقدار ما كتبناه فيه.
بدلاً من ذلك ، يخزن الذيل نهاية قراءة الأنبوب: سيبدأ القارئ في استخدام الأنبوب من هناك. الإزاحة تشير إلى مكان بدء القراءة.
لاحظ أن الذيل يمكن أن يظهر بعد الرأس ، كما هو موضح في الصورة ، لأننا نستخدم مخزنًا مؤقتًا دائريًا / حلقيًا. لاحظ أيضًا أنه عندما لا نقوم بملء الأنبوب بالكامل ، فقد لا يتم استخدام بعض الفتحات - الخلايا الفارغة في المنتصف. إذا كان الأنبوب ممتلئًا (لا توجد قيم فارغة ومساحة خالية في الصفحة) ، فسيتم حظر الكتابة. إذا كان الأنبوب فارغًا (جميع القيم الخالية) ، فسيتم حظر القراءة.
فيما يلي نسخة مختصرة من بنية بيانات C في pipe_fs_i.h:
struct pipe_inode_info {unsigned int head;unsigned int tail;struct pipe_buffer *bufs;};struct pipe_buffer {struct page *page;unsigned int offset, len;};
لقد أغفلنا العديد من الحقول هنا ، ولم نوضح ما هو موجود في صفحة البنية ، لكنها بنية بيانات أساسية لفهم كيفية القراءة والكتابة من الأنبوب.

قراءة وكتابة الأنابيب
لنعد الآن إلى تعريف pipe_write ونحاول فهم إخراج perf الموضح سابقًا. وصف موجز لكيفية عمل pipe_write على النحو التالي:
1. إذا كان خط الأنابيب ممتلئًا ، فانتظر المساحة وأعد التشغيل ؛
2. إذا كان المخزن المؤقت الذي يشير إليه الرأس به مساحة ، فاملأ الفراغ أولاً ؛
3. عندما تكون هناك فتحات حرة ويوجد بايتات متبقية للكتابة ، يتم تخصيص الصفحات الجديدة وتعبئتها وتحديث الرأس .
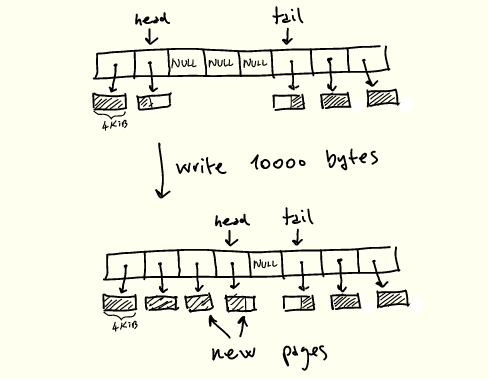
العمل عند الكتابة إلى الأنبوب
العمليات المذكورة أعلاه محمية بقفل يكتسبه pipe_write ويحرره حسب الحاجة .
pipe_read هو نسخة متطابقة من pipe_write ، والفرق هو أن الصفحة يتم استهلاكها ، ويتم تحريرها بعد قراءة الصفحة بالكامل ، ويتم تحديث الذيل.
لذا فإن العملية الحالية تخلق حالة غير سارة للغاية:
-
يتم نسخ كل صفحة مرتين ، مرة من ذاكرة المستخدم إلى kernel ومرة من ذاكرة kernel إلى ذاكرة المستخدم ؛
-
ينسخ صفحة 4KiB في وقت واحد ، متشابكة مع عمليات أخرى مثل المزامنة بين عمليات القراءة والكتابة ، وتخصيص الصفحة وإلغاء تخصيص ؛
-
قد لا تكون الذاكرة قيد المعالجة متجاورة بسبب التخصيص المستمر للصفحات الجديدة ؛
-
يجب الحصول على أقفال الأنابيب وتحريرها طوال الوقت أثناء المعالجة.
على هذا الجهاز ، تبلغ قراءات ذاكرة الوصول العشوائي المتسلسلة حوالي 16 جيجا بايت / ثانية:
sysbench memory --memory-block-size=1G --memory-oper=read --threads=1 run...102400.00 MiB transferred (15921.22 MiB/sec)
بالنظر إلى جميع المشكلات المذكورة أعلاه ، فليس من المستغرب أن تكون أبطأ بمقدار 4 مرات مقارنة بسرعات ذاكرة الوصول العشوائي المتسلسلة أحادية الترابط.
لن يساعد تعديل أحجام المخزن المؤقت أو الأنابيب لتقليل نفقات اتصال النظام والمزامنة ، أو تعديل المعلمات الأخرى كثيرًا. لحسن الحظ ، هناك طريقة لتجنب بطء القراءة والكتابة تمامًا.

تحسين مع الخياطة
هذا النسخ من المخازن المؤقتة من ذاكرة المستخدم إلى النواة والظهر هو شوكة شائعة في جانب الأشخاص الذين يحتاجون إلى IO سريع. الحل الشائع هو إزالة عمليات kernel من المعالجة وتنفيذ عمليات الإدخال / الإخراج مباشرة. على سبيل المثال ، يمكننا التفاعل مباشرة مع بطاقة الشبكة والشبكة بزمن انتقال منخفض لتجاوز النواة.
عادةً عندما نكتب إلى مأخذ أو ملف أو أنبوب في هذه الحالة ، نكتب أولاً إلى بعض المخزن المؤقت في النواة ثم نترك النواة تقوم بعملها. في حالة الأنابيب ، الأنبوب عبارة عن سلسلة من المخازن المؤقتة في النواة. كل هذا الازدواج غير مرغوب فيه إذا كنا نهتم بالأداء.
لحسن الحظ ، يتضمن Linux استدعاءات النظام لتسريع الأمور دون نسخ عندما نريد نقل البيانات حول أنبوب. خاصه:
-
ينقل اللصق البيانات من الأنابيب إلى واصفات الملفات والعكس صحيح ؛
-
ينقل vmsplice البيانات من ذاكرة المستخدم إلى الأنبوب.
النقطة المهمة هي أن كلا العمليتين تعمل دون نسخ أي شيء.
الآن بعد أن عرفنا كيفية عمل الأنابيب ، يمكننا أن نتخيل تقريبًا كيفية عمل هاتين العمليتين: "ينتزعان" مخزنًا مؤقتًا موجودًا من مكان ما ويضعانه في المخزن المؤقت لحلقة الأنبوب ، أو بالعكس تعال ، بدلاً من تخصيص صفحات جديدة عند الحاجة :
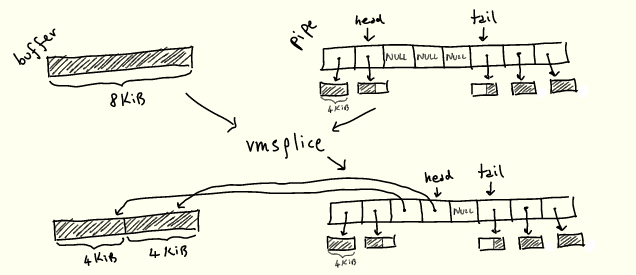
سنرى كيف يعمل قريبا.

تنفيذ الربط
نستبدل الكتابة بـ vmsplice. توقيع vmsplice كما يلي:
struct iovec {void *iov_base; // Starting addresssize_t iov_len; // Number of bytes};// Returns how much we've spliced into the pipessize_t vmsplice(int fd, const struct iovec *iov, size_t nr_segs, unsigned int flags);
fd هو الأنبوب الوجهة و Struct iovec * iov عبارة عن مجموعة من المخازن المؤقتة التي سيتم نقلها إلى الأنبوب. لاحظ أن vmsplice تُرجع الكمية "المقسمة" في الأنبوب ، والتي قد لا تكون الكمية الكاملة ، تمامًا كما ترجع الكتابة الكمية المكتوبة. لا تنس أن الأنابيب مقيدة بعدد الفتحات التي يمكن أن تحتويها في المخزن المؤقت الحلقي ، بينما vmsplice ليس كذلك.
تحتاج أيضًا إلى توخي الحذر عند استخدام vmsplice. يتم نقل ذاكرة المستخدم إلى الأنبوب دون نسخ ، لذلك يجب التأكد من أن جانب القراءة يستخدمها قبل إعادة استخدام المخزن المؤقت المُخيط.
لهذا ، يستخدم fizzbuzz مخطط تخزين مؤقت مزدوج ، والذي يعمل على النحو التالي:
-
قسّم المخزن المؤقت 256 كيلوبايت إلى قسمين ؛
-
ضبط حجم الأنبوب على 128 كيلو بايت يعادل ضبط المخزن المؤقت الدائري للأنبوب بحيث يحتوي على 128 كيلو بايت / 4 كيلوبايت = 32 فتحة ؛
-
اختر بين كتابة النصف الأول من المخزن المؤقت أو استخدام vmsplice لنقله إلى الأنبوب ، وافعل الشيء نفسه بالنسبة للنصف الآخر.
يتم ضبط حجم الأنبوب على 128 كيلوبايت ، ويضمن انتظار vmsplice لإخراج مخزن مؤقت سعة 128 كيلوبايت بالكامل أنه عند اكتمال تكرار vmsplic ، نعلم أن المخزن المؤقت السابق قد تمت قراءته بالكامل - وإلا لا يمكن قراءة المخزن المؤقت الجديد 128 كيلوبايت بالكامل vmsplice في أنبوب 128 كيلوبايت .
الآن ، لم نكتب أي شيء فعليًا إلى المخزن المؤقت ، لكننا سنحتفظ بنظام التخزين المؤقت المزدوج لأن أي برنامج يقوم بالفعل بكتابة المحتوى يحتاج إلى مخطط مماثل.
تبدو حلقة الكتابة الآن كما يلي:
int main() {size_t buf_size = 1 << 18; // 256KiBchar* buf = malloc(buf_size);memset((void*)buf, 'X', buf_size); // output Xschar* bufs[2] = { buf, buf + buf_size/2 };int buf_ix = 0;// Flip between the two buffers, splicing until we're done.while (true) {struct iovec bufvec = {.iov_base = bufs[buf_ix],.iov_len = buf_size/2};buf_ix = (buf_ix + 1) % 2;while (bufvec.iov_len > 0) {ssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, 0);bufvec.iov_base = (void*) (((char*) bufvec.iov_base) + ret);bufvec.iov_len -= ret;}}}
هذه نتيجة الكتابة باستخدام vmsplice بدلاً من الكتابة:
./write --write_with_vmsplice | ./read12.7GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
أدى هذا إلى خفض كمية النسخ المتماثل التي نحتاجها إلى النصف وزاد معدل النقل أكثر من ثلاثة أضعاف إلى 12.7 جيجا بايت / ثانية. بعد تغيير جانب القراءة لاستخدام لصق ، تم التخلص من جميع النسخ ، مما يعطي تسريعًا بمقدار 2.5 مرة أخرى:
./write --write_with_vmsplice | ./read --read_with_splice32.8GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)

تحسينات الصفحة
ماذا بعد؟ دعنا نسأل الكمال:
% perf record -g sh -c './write --write_with_vmsplice | ./read --read_with_splice'33.4GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)[ perf record: Woken up 1 times to write data ][ perf record: Captured and wrote 0.305 MB perf.data (2413 samples) ]% perf report --symbol-filter=vmsplice- 49.59% 0.38% write libc-2.33.so [.] vmsplice- 49.46% vmsplice- 45.17% entry_SYSCALL_64_after_hwframe- do_syscall_64- 44.30% __do_sys_vmsplice+ 17.88% iov_iter_get_pages+ 16.57% __mutex_lock.constprop.03.89% add_to_pipe1.17% iov_iter_advance0.82% mutex_unlock0.75% pipe_lock2.01% __entry_text_start1.45% syscall_return_via_sysret
يتم قضاء معظم الوقت في قفل الأنبوب للكتابة (__mutex_lock.constprop.0) ونقل الصفحات إلى الأنبوب (iov_iter_get_pages). لا يمكن تحسين الكثير بشأن القفل ، ولكن يمكننا تحسين أداء iov_iter_get_pages.
كما يوحي الاسم ، تقوم iov_iter_get_pages بتحويل بنية iovecs التي نقدمها إلى vmsplice إلى صفحات هيكلية لوضعها في خط الأنابيب. لفهم ما تفعله هذه الوظيفة بالفعل ، وكيفية تسريعها ، يجب أن نفهم أولاً كيفية تنظيم CPU و Linux للصفحات.

نظرة سريعة على ترقيم الصفحات
كما تعلم ، لا تشير العمليات مباشرة إلى المواقع في ذاكرة الوصول العشوائي: بدلاً من ذلك ، فإنها تخصص عناوين الذاكرة الظاهرية ، والتي يتم حلها على العناوين الفعلية. يُطلق على هذا التجريد اسم الذاكرة الافتراضية ، ولن نغطي مزاياها المختلفة هنا - ولكن الأهم من ذلك ، أنه يبسط إلى حد كبير تشغيل عمليات متعددة تتنافس على نفس الذاكرة الفعلية.
في أي حال ، عندما نقوم بتنفيذ برنامج وتحميل / تخزين من الذاكرة إلى الذاكرة ، تحتاج وحدة المعالجة المركزية إلى ترجمة العناوين الافتراضية إلى عناوين فعلية. من غير العملي تخزين مخطط من كل عنوان افتراضي إلى كل عنوان فعلي مطابق. لذلك ، يتم تقسيم الذاكرة إلى كتل ذات حجم موحد تسمى الصفحات ، ويتم تعيين الصفحات الافتراضية على الصفحات المادية:
لا يوجد شيء مميز حول 4KiB: تختار كل بنية حجمًا بناءً على المقايضات المختلفة - سنستكشف بعضًا منها قريبًا.
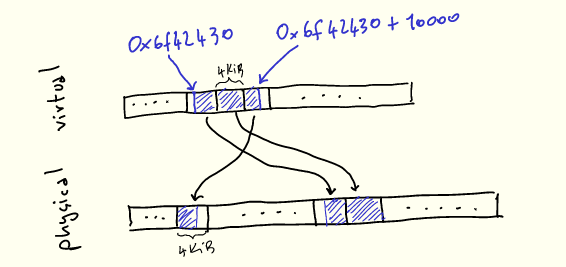
لجعل هذا أكثر وضوحًا ، دعنا نتخيل استخدام malloc لتخصيص 10000 بايت:
void* buf = malloc(10000);printf("%p\n", buf); // 0x6f42430
عندما نستخدمها ، ستظهر وحداتنا البالغة 10 كيلو بايت متجاورة في الذاكرة الافتراضية ، ولكن سيتم تعيينها إلى 3 صفحات فعلية لا يجب أن تكون متجاورة:
تتمثل إحدى مهام kernel في إدارة هذا التعيين ، والذي يتجسد في بنية بيانات تسمى جدول الصفحة. تحدد وحدة المعالجة المركزية بنية جدول الصفحات (لأنها تحتاج إلى فهم جدول الصفحات) ، وتعمل النواة عليه حسب الحاجة. في بنية x86-64 ، يكون جدول الصفحات عبارة عن شجرة ذات 4 مستويات 512 اتجاه ، وهي نفسها موجودة في الذاكرة. كل عقدة في الشجرة (كما خمنت ذلك!) حجمها 4 كيلوبايت ، وكل إدخال داخل العقدة يشير إلى المستوى التالي هو 8 بايت (4KiB / 8bytes = 512). تحتوي هذه الإدخالات على عنوان العقدة التالية والبيانات الوصفية الأخرى.
تحتوي كل عملية على جدول صفحات - بمعنى آخر ، تحتفظ كل عملية بمساحة عنوان ظاهرية. عندما يتحول سياق kernel إلى عملية ، فإنه يعين السجل المحدد CR3 إلى العنوان الفعلي لجذر الشجرة. بعد ذلك ، كلما احتاج عنوان افتراضي إلى الترجمة إلى عنوان مادي ، تقسم وحدة المعالجة المركزية العنوان إلى أجزاء وتستخدمها لاجتياز الشجرة وحساب العنوان الفعلي.
لتقليل تجريد هذه المفاهيم ، إليك وصف بديهي لكيفية حل العنوان الظاهري 0x0000f2705af953c0 لعنوان مادي:
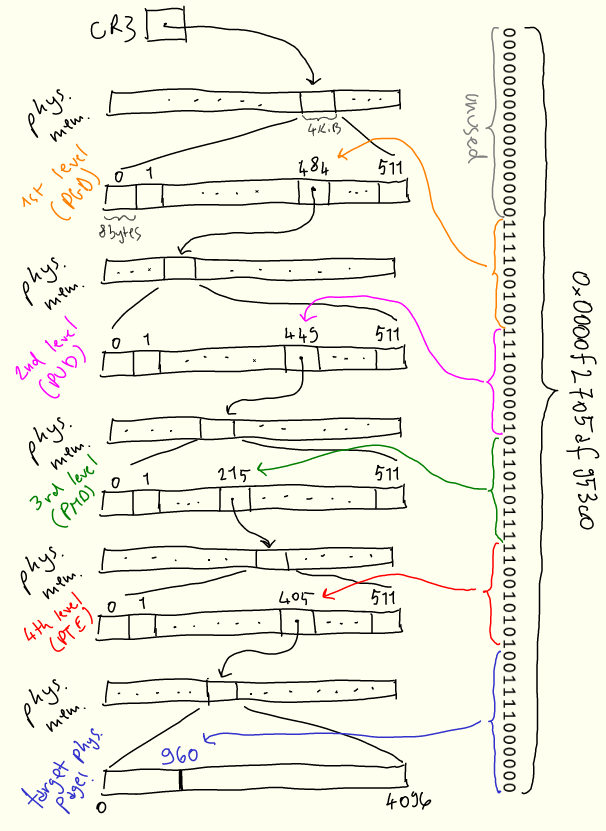
يبدأ البحث في المستوى الأول ، المسمى "الدليل العالمي للصفحة" ، أو PGD ، الذي يتم تخزين موقعه الفعلي في CR3. أول 16 بت من العنوان غير مستخدمة. نأخذ إدخال PGD التالي ذي 9 بتات وننتقل إلى المستوى الثاني "دليل الصفحة العلوي" ، أو PUD. يتم استخدام 9 بتات التالية لتحديد إدخالات من PUD. يتم تكرار العملية في المستويين التاليين ، PMD ("دليل الصفحات الوسطى") و PTE ("إدخال جدول الصفحات"). يخبرنا PTE بمكان الصفحة الفعلية التي يجب البحث عنها ، ثم نستخدم آخر 12 بتًا للعثور على الإزاحة داخل الصفحة.
يسمح الهيكل المتناثر لجدول الصفحات ببناء التعيين بشكل تدريجي حسب الحاجة إلى صفحات جديدة. كلما احتاجت العملية إلى ذاكرة ، ستقوم النواة بتحديث جدول الصفحات بإدخالات جديدة.

دور صفحة الهيكل
تعد بنية بيانات الصفحة الهيكلية جزءًا أساسيًا من هذه الآلية: إنها البنية التي تستخدمها النواة للإشارة إلى صفحة مادية واحدة ، وتخزين عنوانها الفعلي ، وبياناتها الوصفية المتنوعة الأخرى. على سبيل المثال ، يمكننا الحصول على الصفحة الهيكلية من المعلومات الواردة في PTE (المستوى الأخير من جدول الصفحات الموضح أعلاه). بشكل عام ، يتم استخدامه على نطاق واسع في جميع التعليمات البرمجية التي تتعامل مع المعاملات المتعلقة بالصفحة.
在管道场景下,struct page 用于将其数据保存在环形缓冲区中,正如我们已经看到的:
struct pipe_inode_info {unsigned int head;unsigned int tail;struct pipe_buffer *bufs;};struct pipe_buffer {struct page *page;unsigned int offset, len;};
然而,vmsplice 接受虚拟内存作为输入,而 struct page 直接引用物理内存。
因此我们需要将任意的虚拟内存块转换成一组 struct pages。这正是 iov_iter_get_pages 所做的,也是我们花费一半时间的地方:
ssize_t iov_iter_get_pages(struct iov_iter *i, // input: a sized buffer in virtual memorystruct page **pages, // output: the list of pages which back the input bufferssize_t maxsize, // maximum number of bytes to getunsigned maxpages, // maximum number of pages to getsize_t *start // offset into first page, if the input buffer wasn't page-aligned);
struct iov_iter 是一种 Linux 内核数据结构,表示遍历内存块的各种方式,包括 struct iovec。在我们的例子中,它将指向 128KiB 的缓冲区。vmsplice 使用 iov_iter_get_pages 将输入缓冲区转换为一组 struct pages,并保存它们。既然已经知道了分页的工作原理,你可以大概想象一下 iov_iter_get_pages 是如何工作的,下一节详细解释它。
我们已经快速了解了许多新概念,概括如下:
-
现代 CPU 使用虚拟内存进行处理;
-
内存按固定大小的页面进行组织;
-
CPU 使用将虚拟页映射到物理页的页表,把虚拟地址转换为物理地址;
-
内核根据需要向页表添加和删除条目;
-
管道是由对物理页的引用构成的,因此 vmsplice 必须将一系列虚拟内存转换为物理页,并保存它们。

获取页的成本
在 iov_iter_get_pages 中所花费的时间,实际上完全花在另一个函数,get_user_page_fast 中:
perf report -g --symbol-filter=iov_iter_get_pages- 17.08% 0.17% write [kernel.kallsyms] [k] iov_iter_get_pages- 16.91% iov_iter_get_pages- 16.88% internal_get_user_pages_fast11.22% try_grab_compound_head
get_user_pages_fast 是 iov_iter_get_ pages 的简化版本:
int get_user_pages_fast(// virtual address, page alignedunsigned long start,// number of pages to retrieveint nr_pages,// flags, the meaning of which we won't get intounsigned int gup_flags,// output physical pagesstruct page **pages)
这里的“user”(与“kernel”相对)指的是将虚拟页转换为对物理页的引用。
为了得到 struct pages,get_user_pages_fast 完全按照 CPU 操作,但在软件中:它遍历页表以收集所有物理页,将结果存储在 struct pages 里。我们的例子中是一个 128KiB 的缓冲区和 4KiB 的页,因此 nr_pages = 32。get_user_page_fast 需要遍历页表树,收集 32 个叶子,并将结果存储在 32 个 struct pages 中。
get_user_pages_fast 还需要确保物理页在调用方不再需要之前不会被重用。这是通过在内核中使用存储在 struct page 中的引用计数来实现的,该计数用于获知物理页在将来何时可以释放和重用。get_user_pages_fast 的调用者必须在某个时候使用 put_page 再次释放页面,以减少引用计数。
最后,get_user_pages_fast 根据虚拟地址是否已经在页表中而表现不同。这就是 _fast 后缀的来源:内核首先将尝试通过遍历页表来获取已经存在的页表条目和相应的 struct page,这成本相对较低,然后通过其他更高成本的方法返回生成 struct page。我们在开始时memset内存的事实,将确保永远不会在 get_user_pages_fast 的“慢”路径中结束,因为页表条目将在缓冲区充满“X”时创建。
注意,get_user_pages 函数族不仅对管道有用——实际上它在许多驱动程序中都是核心。一个典型的用法与我们提及的内核旁路有关:网卡驱动程序可能会使用它将某些用户内存区域转换为物理页,然后将物理页位置传递给网卡,并让网卡直接与该内存区域交互,而无需内核参与。

大体积页面
到目前为止,我们所呈现的页大小始终相同——在 x86-64 架构上为 4KiB。但许多 CPU 架构,包括 x86-64,都包含更大的页面尺寸。x86-64 的情况下,我们不仅有 4KiB 的页(“标准”大小),还有 2MiB 甚至 1GiB 的页(“巨大”页)。在本文的剩余部分中,我们只讨论2MiB的大页,因为 1GiB 的页相当少见,对于我们的任务来说纯属浪费。

当今常用架构中的页大小,来自维基百科
大页的主要优势在于管理成本更低,因为覆盖相同内存量所需的页更少。此外其他操作的成本也更低,例如将虚拟地址解析为物理地址,因为所需要的页表少了一级:以一个 21 位的偏移量代替页中原来的12位偏移量,从而少一级页表。
这减轻了处理此转换的 CPU 部分的压力,因而在许多情况下提高了性能。但是在我们的例子中,压力不在于遍历页表的硬件,而在内核中运行的软件。
在 Linux 上,我们可以通过多种方式分配 2MiB 大页,例如分配与 2MiB 对齐的内存,然后使用 madvise 告诉内核为提供的缓冲区使用大页:
void* buf = aligned_alloc(1 << 21, size);madvise(buf, size, MADV_HUGEPAGE)
切换到大页又给我们的程序带来了约 50% 的性能提升:
./write --write_with_vmsplice --huge_page | ./read --read_with_splice51.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
然而,提升的原因并不完全显而易见。我们可能会天真地认为,通过使用大页, struct page 将只引用 2MiB 页,而不是 4KiB 页面。
遗憾的是,情况并非如此:内核代码假定 struct page 引用当前架构的“标准”大小的页。这种实现作用于大页(通常Linux称之为“复合页面”)的方式是,“头” struct page 包含关于背后物理页的实际信息,而连续的“尾”页仅包含指向头页的指针。
因此为了表示 2MiB 的大页,将有1个“头”struct page,最多 511 个“尾”struct pages。或者对于我们的 128KiB 缓冲区来说,有 31个尾 struct pages:
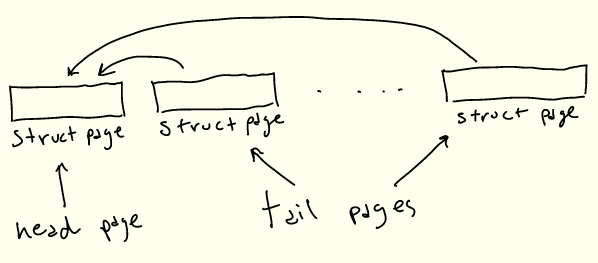
即使我们需要所有这些 struct pages,最后生成它的代码也会大大加快。找到第一个条目后,可以在一个简单的循环中生成后面的 struct pages,而不是多次遍历页表。这样就提高了性能!

Busy looping
我们很快就要完成了,我保证!再看一下 perf 的输出:
- 46.91% 0.38% write libc-2.33.so [.] vmsplice- 46.84% vmsplice- 43.15% entry_SYSCALL_64_after_hwframe- do_syscall_64- 41.80% __do_sys_vmsplice+ 14.90% wait_for_space+ 8.27% __wake_up_common_lock4.40% add_to_pipe+ 4.24% iov_iter_get_pages+ 3.92% __mutex_lock.constprop.01.81% iov_iter_advance+ 0.55% import_iovec+ 0.76% syscall_exit_to_user_mode1.54% syscall_return_via_sysret1.49% __entry_text_start
现在大量时间花费在等待管道可写(wait_for_space),以及唤醒等待管道填充内容的读程序(__wake_up_common_lock)。
为了避免这些同步成本,如果管道无法写入,我们可以让 vmsplice 返回,并执行忙循环直到写入为止——在用 splice 读取时做同样的处理:
...// SPLICE_F_NONBLOCK will cause `vmsplice` to return immediately// if we can't write to the pipe, returning EAGAINssize_t ret = vmsplice(STDOUT_FILENO, &bufvec, 1, SPLICE_F_NONBLOCK);if (ret < 0 && errno == EAGAIN) {continue; // busy loop if not ready to write}...
通过忙循环,我们的性能又提高了25%:
./write --write_with_vmsplice --huge_page --busy_loop | ./read --read_with_splice --busy_loop62.5GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)

总结
通过查看 perf 输出和 Linux 源码,我们系统地提高了程序性能。在高性能编程方面,管道和拼接并不是真正的热门话题,而我们这里所涉及的主题是:零拷贝操作、环形缓冲区、分页与虚拟内存、同步开销。
尽管我省略了一些细节和有趣的话题,但这篇博文还是已经失控而变得太长了:
-
在实际代码中,缓冲区是分开分配的,通过将它们放置在不同的页表条目中来减少页表争用(FizzBuzz程序也是这样做的)。
-
记住,当使用 get_user_pages 获取页表条目时,其 refcount 增加,而 put_page 减少。如果我们为两个缓冲区使用两个页表条目,而不是为两个缓冲器共用一个页表条目的话,那么在修改 refcount 时争用更少。
-
通过用taskset将./write和./read进程绑定到两个核来运行测试。
-
资料库中的代码包含了我试过的许多其他选项,但由于这些选项无关紧要或不够有趣,所以最终没有讨论。
-
资料库中还包含get_user_pages_fast 的一个综合基准测试,可用来精确测量在用或不用大页的情况下运行的速度慢多少。
-
一般来说,拼接是一个有点可疑/危险的概念,它继续困扰着内核开发人员。
请让我知道本文是否有用、有趣或不一定!

致谢
非常感谢 Alexandru Scvorţov、Max Staudt、Alex Appetiti、Alex Sayers、Stephen Lavelle、Peter Cawley和Niklas Hambüchen审阅了本文的草稿。Max Staudt 还帮助我理解了 get_user_page 的一些微妙之处。
1. 这将在风格上类似于我的atan2f性能调研(https://mazzo.li/posts/vectorized-atan2.html),尽管所讨论的程序仅用于学习。此外,我们将在不同级别上优化代码。调优 atan2f 是在汇编语言输出指导下进行的微优化,调优管道程序则涉及查看 perf 事件,并减少各种内核开销。
2. 本测试在英特尔 Skylake i7-8550U CPU 和 Linux 5.17 上运行。你的环境可能会有所不同,因为在过去几年中,影响本文所述程序的 Linux 内部结构一直在不断变化,并且在未来版本中可能还会调整。
3. “FizzBuzz”据称是一个常见的编码面试问题,虽然我个人从来没有被问到过该问题,但我有确实发生过的可靠证据。
4. 尽管我们固定了缓冲区大小,但即便我们使用不同的缓冲区大小,考虑到其他瓶颈的影响,(吞吐量)数字实际也并不会有很大差异。
5. 关于有趣的细节,可随时参考资料库。一般来说,我不会在这里逐字复制代码,因为细节并不重要。相反,我将贴出更新的代码片段。
6. 注意,这里我们分析了一个包括管道读取和写入的shell调用——默认情况下,perf record跟踪所有子进程。
7. 分析该程序时,我注意到 perf 的输出被来自“Pressure Stall Information”基础架构(PSI)的信息所污染。因此这些数字取自一个禁用PSI后编译的内核。这可以通过在内核构建配置中设置 CONFIG_PSI=n 来实现。在NixOS 中:
boot.kernelPatches = [{name = "disable-psi";patch = null;extraConfig = ''PSI n'';}];
此外,为了让 perf 能正确显示在系统调用中花费的时间,必须有内核调试符号。如何安装符号因发行版而异。在最新的 NixOS 版本中,默认情况下会安装它们。
8. 假如你运行了 perf record -g,可以在 perf report 中用 + 展开调用图。
9. 被称为 tmp_page 的单一“备用页”实际上由 pipe_read 保留,并由pipe_write 重用。然而由于这里始终只是一个页面,我无法利用它来实现更高的性能,因为在调用 pipe_write 和 pipe_ read 时,页面重用会被固定开销所抵消。
10. 从技术上讲,vmsplice 还支持在另一个方向上传输数据,尽管用处不大。如手册页所述:
vmsplice实际上只支持从用户内存到管道的真正拼接。反方向上,它实际上只是将数据复制到用户空间。
11. Travis Downs 指出,该方案可能仍然不安全,因为页面可能会被进一步拼接,从而延长其生命期。这个问题也出现在最初的 FizzBuzz 帖子中。事实上,我并不完全清楚不带 SPLICE_F_GIFT 的 vmsplice 是否真的不安全——vmsplic 的手册页说明它是安全的。然而,在这种情况下,绝对需要特别小心,以实现零拷贝管道,同时保持安全。在测试程序中,读取端将管道拼接到/dev/null 中,因此可能内核知道可以在不复制的情况下拼接页面,但我尚未验证这是否是实际发生的情况。
12. 这里我们呈现了一个简化模型,其中物理内存是一个简单的平面线性序列。现实情况复杂一些,但简单模型已能说明问题。
13. 可以通过读取 /proc/self/pagemap 来检查分配给当前进程的虚拟页面所对应的物理地址,并将“页面帧号”乘以页面大小。
14. 从 Ice Lake 开始,英特尔将页表扩展为5级,从而将最大可寻址内存从256TiB 增加到 128PiB。但此功能必须显式开启,因为有些程序依赖于指针的高 16 位不被使用。
15. 页表中的地址必须是物理地址,否则我们会陷入死循环。
16. 注意,高 16 位未使用:这意味着我们每个进程最多可以处理 248 − 1 字节,或 256TiB 的物理内存。
17. struct page 可能指向尚未分配的物理页,这些物理页还没有物理地址和其他与页相关的抽象。它们被视为对物理页面的完全抽象的引用,但不一定是对已分配的物理页面的引用。这一微妙观点将在后面的旁注中予以说明。
18. 实际上,管道代码总是在 nr_pages = 16 的情况下调用 get_user_pages_fast,必要时进行循环,这可能是为了使用一个小的静态缓冲区。但这是一个实现细节,拼接页面的总数仍将是32。
19. 以下部分是本文不需要理解的微妙之处!
如果页表不包含我们要查找的条目,get_user_pages_fast 仍然需要返回一个 struct page。最明显的方法是创建正确的页表条目,然后返回相应的 struct page。
然而,get_user_pages_fast 仅在被要求获取 struct page 以写入其中时才会这样做。否则它不会更新页表,而是返回一个 struct page,给我们一个尚未分配的物理页的引用。这正是 vmsplice 的情况,因为我们只需要生成一个 struct page 来填充管道,而不需要实际写入任何内存。
换句话说,页面分配会被延迟,直到我们实际需要时。这节省了分配物理页的时间,但如果页面从未通过其他方式填充错误,则会导致重复调用 get_user_pages_fast 的慢路径。
因此,如果我们之前不进行 memset,就不会“手动”将错误页放入页表中,结果是不仅在第一次调用 get_user_pages_fast 时会陷入慢路径,而且所有后续调用都会出现慢路径,从而导致明显地减速(25GiB/s而不是30GiB/s):
./write --write_with_vmsplice --dont_touch_pages | ./read --read_with_splice25.0GiB/s, 256KiB buffer, 40960 iterations (10GiB piped)
此外,在使用大页时,这种行为不会表现出来:在这种情况下,get_user_pages_fast 在传入一系列虚拟内存时,大页支持将正确地填充错误页。
如果这一切都很混乱,不要担心,get_user_page 和 friends 似乎是内核中非常棘手的一角,即使对于内核开发人员也是如此。
20. 仅当 CPU 具有 PDPE1GB 标志时。
21. 例如,CPU包含专用硬件来缓存部分页表,即“转换后备缓冲区”(translation lookaside buffer,TLB)。TLB 在每次上下文切换(每次更改 CR3 的内容)时被刷新。大页可以显著减少 TLB 未命中,因为 2MiB 页的单个条目覆盖的内存是 4KiB 页面的 512 倍。
22. إذا كنت تفكر في "سيء للغاية!" يتم بذل العديد من الجهود لتبسيط و / أو تحسين هذا الوضع. تتضمن النوى الحديثة (منذ 5.17) نوعًا جديدًا ، سجل هيكلي ، لتحديد صفحات الرأس بشكل واضح. يقلل هذا من الحاجة إلى التحقق مما إذا كانت الصفحة الهيكلية هي الصفحة الأولى أو الأخيرة في وقت التشغيل ، وبالتالي تحسين الأداء. تهدف الجهود الأخرى إلى إزالة صفحات البنية الإضافية تمامًا ، على الرغم من أنني لا أعرف كيف.
